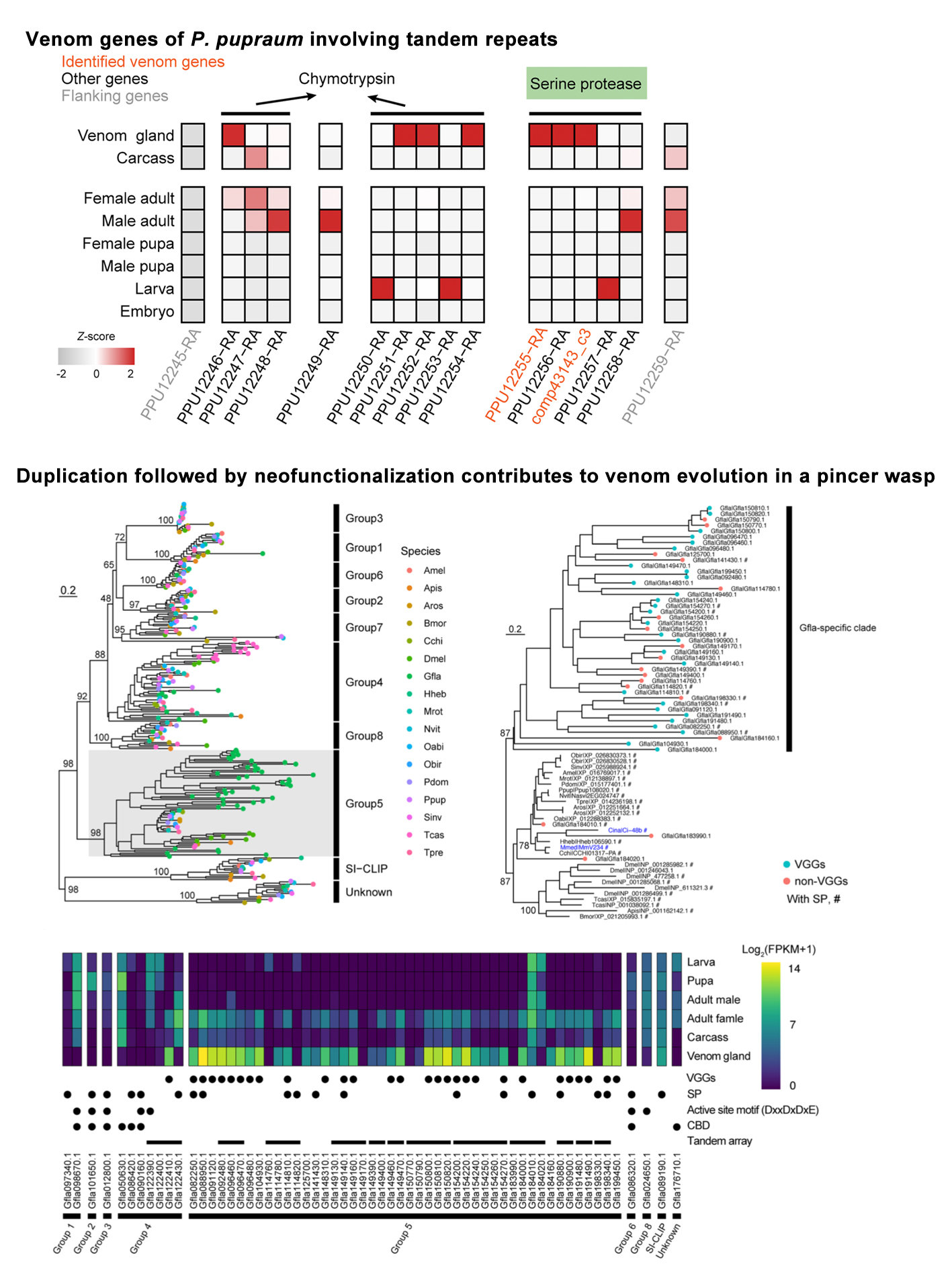
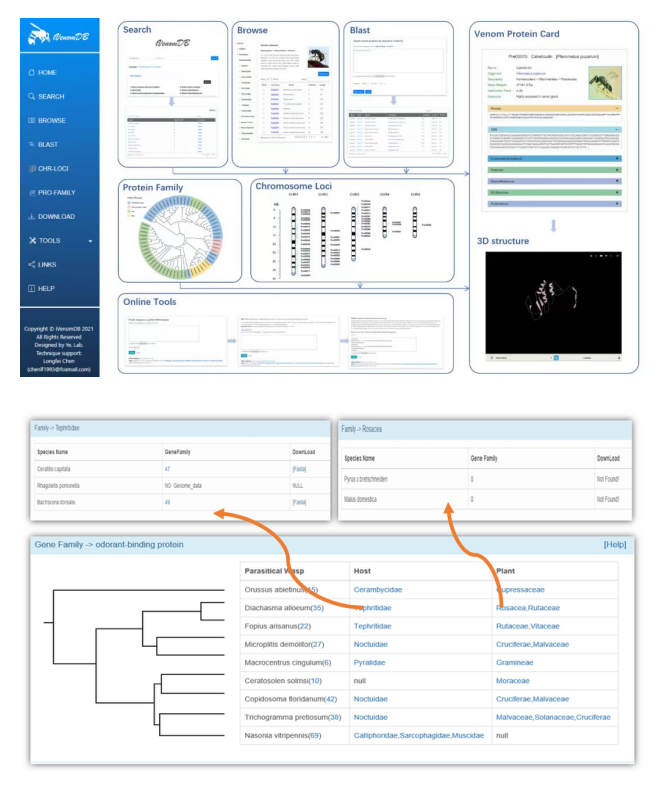
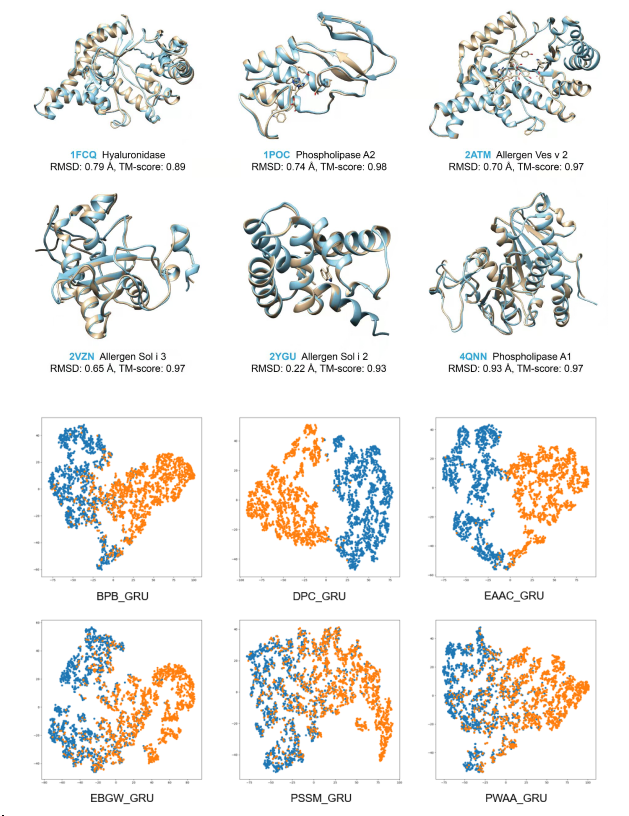
Bioinformatics algorithm and tools development refer to the process of creating computational methods and software applications specifically designed for analyzing biological data. These algorithms and tools are essential in tackling complex biological questions, interpreting genomic information, studying protein structures, and understanding biological processes at a molecular level. In bioinformatics, deep learning has emerged as a powerful tool for analyzing biological data, discovering patterns, and making predictions in areas such as genomics, proteomics, drug discovery, and personalized medicine. The content including (1) Genomic Sequencing Analysis: Deep learning models are used to analyze and interpret genomic sequences, identify genetic variations, predict gene function, and classify sequences based on structure and function. (2) Protein Structure Prediction: Deep learning algorithms can predict protein structures, infer protein-protein interactions, and classify protein functions based on sequence and structural information. (3) Drug Discovery: Deep learning is applied in virtual screening of drug compounds, predicting drug-target interactions, and optimizing drug design for more effective and targeted therapies. (4) Disease Diagnosis and Prediction: Deep learning models are used to analyze clinical data, medical images, and genetic information to diagnose diseases, predict disease progression, and stratify patients for personalized treatment.